Intro:
I had a plan to make some kind of map data in Houdini. There’s plenty of built in functionality to do these kind of things so I approached it simply, using the “cluster” SOP to create a cluster attribute and then further operate on those elsewhere.
I won’t get distracted with all the other parts of the project here, but I do want to make a note about the interesting parts of dealing with the aggregation and organisation of these clusters. This seems like a situation which could recur and is a bit more abstract than my specific use case.
Clustering:
So – here’s how cluster SOP works:
Give it a remeshed grid, and you get a cluster attribute (visualised here by random colours)

Not super interesting, eh? Well, you can use noise to alter how the cluster is calculated. This bland example uses P, so it is just a distance function (voronoi style). If we noise up the P, the edges will get more perturbed etc. This can be done in various ways, but I added a ‘cluster_edges’ noise attribute and added a second atribute to the cluster SOP to bring in this noise and use it in the calculations.

A bit better – but we want a bit more organic noise and less regular blob shaped regions. So – just dial up all the chaos!

Much nicer.
At this point I proceeded to do other stuff, but soon discovered I had inadvertently created an issue! In this noisy and chaotic version, you can spot that one colour (one cluster) appears in several spots. This means they are treated as one mesh in later stages when iterating with foreach loops or so on.
Luckily, this is pretty simple to fix – using a foreach loop based on cluster, the output has all the clusters as separated geometry. This means that a connectivity SOP can separate the pieces nicely. To allow this, the cluster point attribute gets promoted to primitive, for the loop and connectivity SOP to utilise.
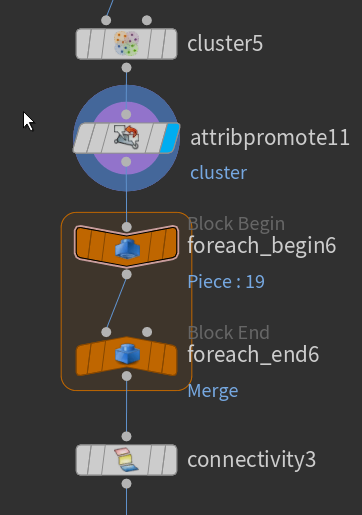

The result is this – much better, each area is properly separated with its own cluster attribute created in the connectivity SOP.
I continued the task, but noticed some related issue – it seems separating these chunks has some more edge cases to be handled. In addition, we can see a huge disparity in the sizes of the clusters – this is intentional and desired, but also I want a way to deal with the tiny fragmented parts which are too small to be useful.
First – the edge case.
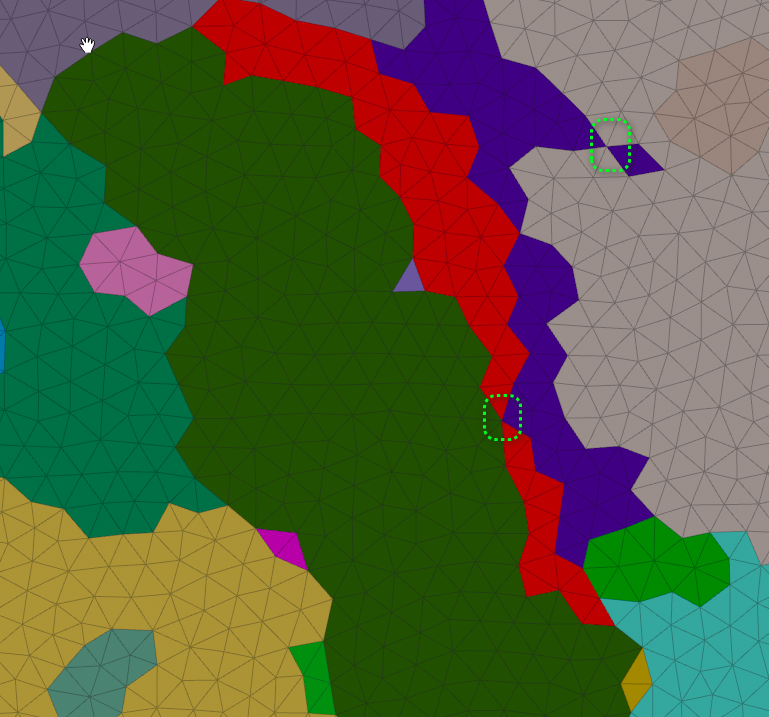
These sections have a part joined by one point, marked in green. This would be better separated into 2 pieces, which can then be handled the same way for small fragments etc.
We have a built-in method in Houdini to deal with this, using our friend polydoctor SOP:

The trick here is to use the manifold calculation – this will help by creating multiple indices for a cluster which has these non manifold parts. Thanks to probiner over on Discord for the tip (https://discord.com/channels/230123485668573184/231830113304444928)
So doing that, we are here:
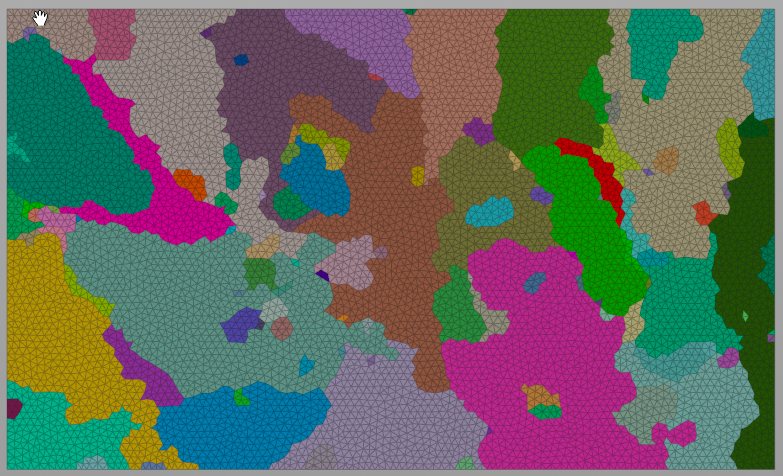
At this point, we have a decent set of well defined and edge-case free clusters/meshes to do other things with!
Tidying up the mess:
The chaos is great, but those many smaller 1 or 2 primitive clusters are not meaningful or useful for my use case. In the more abstract view, it seems to make sense that one would want a method of setting a minimum limit in any use case, so that became my next objective.
My way of problem solving can itself be a tad chaotic, so I dove in, trying out a few different methods, and I can say that I possibly underestimated the complexity and nuances at the start.
At first, I used a foreach loop to iterate the clusters, pulling in the map to a wrangle’s 2nd input, and was staying in node-land, but this began to get a little confusing and I decided maybe this could be dealt with more smoothly in a detail wrangle. I am an advocate of trying to use the best tool for the job in the context, and this felt more suitable. I was partially wrong, as it happens, but this was the strategy – detail wrangle it all.
Detail wrangle what exactly though? Well, the idea would be:
- figure out for a given cluster:
- what is its area?
- which other clusters neigbour it?
- make some decisions to convert cluster one to the neighbour cluster, if it is below the area threshold
If we do this for all clusters, then it should be tidy, right?

Well it worked! (animated for effect, it is almost instant in reality)
This was my first attempt in vex:
float AREATHRESHOLD = 1.0;
int NUMCLUSTERS = detail(0, "cluster");
int DEBUG = 0;
int cached_cluster[];
float cached_area[];
int cycle = min(chi("cycle"), NUMCLUSTERS);
// cache the cluster and area attrs per prim
for(int i=0; i<nprimitives(0); i++)
{
cached_cluster[i] = prim(0, "cluster", i);
cached_area[i] = prim(0, "area", i);
}
if(DEBUG==1) printf("Num clusters: %d",NUMCLUSTERS);
// iterate each cluster value
for(int i=0; i<=cycle; i++)
{
int thiscluster = i;
int clusterprims[] = find(cached_cluster, thiscluster);
float thisarea = cached_area[clusterprims[0]];
if(thisarea < AREATHRESHOLD)
{
if(DEBUG==1) printf("\tcluster below threshold: %d\n",thiscluster);
if(DEBUG==1) printf("\tcprims---%d\n",clusterprims);
// find neighbour with largest area
int nclusters[];
float nareas[];
foreach(int cp;clusterprims)
{
int pns[] = polyneighbours(0,cp);
if(DEBUG==1) printf("\t\t%d neighbours: %d\n",cp,pns);
foreach(int pn; pns)
{
int pncluster = cached_cluster[pn];
float pnarea = cached_area[pn];
//printf("%d --- %d\n",pncluster,pnarea);
// if cluster is not the same as our own,
// it is a neighbour region
if (pncluster != thiscluster)
{
// collect neighbour data
if(find(nclusters, pncluster)<0)
{
append(nclusters, pncluster);
append(nareas, pnarea);
}
}
}
}
if(DEBUG==1) printf("%d --- %d\n",nclusters,nareas);
// get largest area neighbour
float maxarea = max(nareas);
int maxidx = find(nareas, maxarea);
int maxcluster = nclusters[maxidx];
// set this cluster to that one
float newarea = maxarea + thisarea;
foreach(int ncp; clusterprims)
{
cached_cluster[ncp] = maxcluster;
cached_area[ncp] = newarea;
}
}
}
//output data
for(int i=0; i<nprimitives(0); i++)
{
setprimattrib(0, "cluster", i, cached_cluster[i], "set");
setprimattrib(0, "area", i, cached_area[i], "set");
}
With VEX in wrangles which operate over points/prims etc. one can sometimes fall into a trap where it becomes confusing to differentiate the input attributes, the changes inside the wrangle, and the output attributes. It’s a necessity to take advantage of the SIMD benefits, but can complicate things sometimes. With detail wrangles, however, it is a bit more straightforward – just that you need to marshal your own data and the convenience of @primnum etc. are not available. You get total control, however.
After getting this working I was quite pleased as it did the job I wanted it to. Small clusters get aggregated with their largest neighbour.
Additionally, I tried this on a few test cases, one of which was a larger grid, and the slowdown was… _significant_. Checking my vex, there’s a lot of not-optimal stuff happening, so this is not such a surprise. What I made was fit for purpose for what I originally needed, but this slow performance was mildly nagging at me.
Optimising the solution:
I was discussing this with probiner on the discord, and he offered some interesting insights and ideas of different approaches. I wanted to keep plugging away with my vex-based attempt, and decided to optimise it a bit more. I felt ashamed at my messy solution. On the large grid test case, the aggregation was taking ~60 seconds to run on my i9 CPU which was not acceptable.
I planned first to clean up anything obvious in my VEX.
- There were some errors – as usual
- “if(find(nclusters, pncluster<0))” has a typo – meaning it adds duplicates to the array – not a huge cost but something..
- There were various places where static data was being looked up each iteration, eg:
- polyneighbours to get neighbour indices while iterating
- clusterprims[] being filled using ‘find’
- etc.
- Critically, when iterating the cluster’s primitives, there was no filtering for the border prims – meaning lots of wasted work.
So I did a clean up of this kind of slow/lazy data handling and got things a bit more clean.
‘store_prim_data’ is a primitive wrangle which caches the “polyneighbours” result per primitive. Then the new, cleaner aggregate detail wrangle is as follows:
float AREATHRESHOLD = 1.0;
int NUMCLUSTERS = detail(0, "cluster");
int DEBUG = 0;
int cached_cluster[];
float cached_area[];
int cycle = chi("cycle");
// cache the cluster and area attrs per prim
for(int i=0; i<nprimitives(0); i++)
{
cached_cluster[i] = prim(0, "cluster", i);
cached_area[i] = prim(0, "area", i);
}
if(DEBUG==1) printf("Num clusters: %d",NUMCLUSTERS);
// iterate each cluster value
for(int i=0; i<=cycle; i++)
{
int thiscluster = i;
int clusterprims[] = find(cached_cluster, thiscluster);
float thisarea = cached_area[clusterprims[0]];
if(thisarea < AREATHRESHOLD)
{
if(DEBUG==1) printf("\tcluster below threshold: %d\n",thiscluster);
if(DEBUG==1) printf("\tcprims---%d\n",clusterprims);
// find neighbour with largest area
int nclusters[];
float nareas[];
foreach(int cp;clusterprims)
{
if(inprimgroup(0, "edgeprims", cp)==1)
{
//int pns[] = polyneighbours(0,cp);
int pns[] = prim(0,"nbors",cp);
if(DEBUG==1) printf("\t\t%d neighbours: %d\n",cp,pns);
foreach(int pn; pns)
{
int pncluster = cached_cluster[pn];
float pnarea = cached_area[pn];
//printf("%d --- %d\n",pncluster,pnarea);
// if cluster is not the same as our own,
// it is a neighbour region
if (pncluster != thiscluster)
{
// collect neighbour data
if(find(nclusters, pncluster)<0)
{
append(nclusters, pncluster);
append(nareas, pnarea);
}
//printf("%d --- %d\n",nclusters,nareas);
}
}
}
}
if(DEBUG==1) printf("%d --- %d\n",nclusters,nareas);
// get largest area neighbour
float maxarea = max(nareas);
int maxidx = find(nareas, maxarea);
int maxcluster = nclusters[maxidx];
// set this cluster to that one
float newarea = maxarea + thisarea;
foreach(int ncp; clusterprims)
{
cached_cluster[ncp] = maxcluster;
cached_area[ncp] = newarea;
}
}
}
//output data
for(int i=0; i<nprimitives(0); i++)
{
setprimattrib(0, "cluster", i, cached_cluster[i], "set");
setprimattrib(0, "area", i, cached_area[i], "set");
}
This version when run on the large map test sat around ~25 seconds. Those minor changes were not really game changing, but only dealing with the border primitives made a significant difference.
At this point I was thinking of ways to reduce more these overheads – the meaningful change is cluster to cluster, the primitives and handling them is a secondary concern. So I decided to try another round of changes. This time:
- Do a prepass
- store lots of useful data once, in detail attributes
- arrays or dictionaries so that the data can be accessed per cluster easily
- run the algorithm on the clusters in order of sorted area
- This hopefully means all the small stuff is at the start of the array and gets processed, and all the later ones just ‘early out’ via the area check.
- store lots of useful data once, in detail attributes
- Run a similar algorithm as the previous, but using cached/prepass data as much as possible.
Thinking about this, instead of calculating the neighbours of a primitive and which s the largest etc. I want to calculate the cluster’s neighbour with the largest area. And this neighbour is just one static value, where previously I had been collecting arrays and checking them etc. This is done in the prepass now.
So now this is the node setup:

‘store_neighbours_per_prim’ just does the following vex over primitives filtered by the edge_prim group set earlier.
int nbors[] = polyneighbours(0,@primnum);
i[]@nbors = nbors;‘prim_sets_to_detail’ is our prepass and does the following:
dict d_cluster_prims;
dict d_largest_nb_cluster;
dict d_largest_nb_idx;
dict d_largest_nb_area;
int num_clusters = detail(0,"cluster",0);
// sort areas
float cluster_areas[];
for(int i=0; i<=num_clusters; i++)
{
int clusterprim = findattribval(0, "prim", "cluster", i);
append(cluster_areas, float(prim(0, "area", clusterprim)));
}
int clusters_by_area[] = argsort(cluster_areas);
//printf("%d\n",clusters_by_area);
setdetailattrib(0,"clusters_by_area",clusters_by_area,"set");
//printf("%d\n",num_clusters);
for(int i=0; i<=num_clusters; i++)
{
int thiscluster = clusters_by_area[i];
// get cluster sets into dictionary
int clusterprims[] = findattribval(0, "prim", "cluster", thiscluster);
//printf("%d --- %d\n%d\n",i, thiscluster, clusterprims);
d_cluster_prims[itoa(thiscluster)] = clusterprims;
// get largest neighbour
int largest_nb_idx = -1;
int largest_nb_cluster = -1;
float largest_nb_area = -1;
// printf("%d\n",clusterprims);
foreach(int cp; clusterprims)
{
if(inprimgroup(0,"edgeprims",cp))
{
int nbors[] = prim(0, "nbors", cp);
foreach(int nb; nbors)
{
int nbcluster = prim(0,"cluster",nb);
float nbarea = prim(0,"area",nb);
//printf("%d --- %d\n",nbcluster,nbarea);
// if cluster is not the same as our own,
// it is a neighbour region
if (nbcluster != thiscluster)
{
if(nbarea>largest_nb_area)
{
largest_nb_idx = nb;
largest_nb_cluster = nbcluster;
largest_nb_area = nbarea;
}
//printf("%d --- %d --- %d\n",largest_nb_idx,largest_nb_cluster,largest_nb_area);
}
}
}
}
// we should have the data by heuristic used
d_largest_nb_cluster[itoa(thiscluster)] = largest_nb_cluster;
d_largest_nb_idx[itoa(thiscluster)] = largest_nb_idx;
d_largest_nb_area[itoa(thiscluster)] = largest_nb_area;
}
//printf("%d\n",d_cluster_prims);
setdetailattrib(0,"d_cluster_prims",d_cluster_prims,"set");
setdetailattrib(0,"d_largest_nb_cluster",d_largest_nb_cluster,"set");
setdetailattrib(0,"d_largest_nb_idx",d_largest_nb_idx,"set");
setdetailattrib(0,"d_largest_nb_area",d_largest_nb_area,"set");
There id probably some redundancy and clearing still to be done but the broad strokes are as follows:
- get a sorted list of cluster indices by cluster area
- iterate primitives per cluster, filtered by edge prims, and accumulate largest neighbour data if a larger neighbour is found
- store all data in dictionaries where cluster index is the key:
- neighbour datas
- cluster’s primitive ids
Then the main VEX in ‘aggregate’ looks like this:
float AREATHRESHOLD = 1.0;
int NUMCLUSTERS = detail(0, "cluster");
int DEBUG = 0;
int cached_cluster[];
float cached_area[];
int clusters_by_area[];
dict d_largest_nb_cluster;
dict d_largest_nb_idx;
dict d_largest_nb_area;
dict cached_clusterprims;
int cycle = min(chi("cycle"), NUMCLUSTERS);
// cache the cluster and area attrs per prim
//printf("Caching data:\n");
cached_clusterprims = detail(0,"d_cluster_prims",0);
d_largest_nb_cluster = detail(0,"d_largest_nb_cluster",0);
d_largest_nb_idx = detail(0,"d_largest_nb_idx",0);
d_largest_nb_area = detail(0,"d_largest_nb_area",0);
clusters_by_area = detail(0, "clusters_by_area",0);
for(int i=0; i<nprimitives(0); i++)
{
cached_cluster[i] = prim(0, "cluster", i);
cached_area[i] = prim(0, "area", i);
}
// We'll update all the dictionaries
// and cached data as we go..
//printf("%d\n", clusters_by_area);
if(DEBUG==1) printf("Num clusters: %d\n",NUMCLUSTERS);
// iterate each cluster value
for(int i=0; i<=cycle; i++)
{
//printf("%d --- %d\n", i, clusters_by_area[i]);
int thiscluster = clusters_by_area[i];
int clusterprims[] = cached_clusterprims[itoa(thiscluster)];
int clusterprimid_first = clusterprims[0];
//printf("%d -- %d -- %d --\n",thiscluster, clusterprimid, clusterprims);
float thisarea = cached_area[clusterprimid_first];
// note here the neigbour data is not all naighbours
// it is calculated in prepass, and is the
// neighbour matching a heuristic (largest area here)
if(thisarea < AREATHRESHOLD)
{
if(DEBUG==1) printf("\tcluster %d below threshold:\n",thiscluster);
if(DEBUG==1) printf("\t\tclusterprimid_first: %d\n",clusterprimid_first);
if(DEBUG==1) printf("\t\tthisarea: %d\n\n",thisarea);
int nbor_idx = d_largest_nb_idx[itoa(thiscluster)];
if(DEBUG==1) printf("\t\tnbor_idx: %d\n",nbor_idx);
float nbor_area = d_largest_nb_area[itoa(thiscluster)];
if(DEBUG==1) printf("\t\tnbor_area: %d\n",nbor_area);
int nbor_cluster = d_largest_nb_cluster[itoa(thiscluster)];
if(DEBUG==1) printf("\t\tnbor_cluster: %d\n",nbor_cluster);
// get neighbour's neighbour data
int n_nbor_idx = d_largest_nb_idx[itoa(nbor_cluster)];
float n_nbor_area = d_largest_nb_area[itoa(nbor_cluster)];
int n_nbor_cluster = d_largest_nb_cluster[itoa(nbor_cluster)];
// calc combined values
float newarea = nbor_area + thisarea;
int tmp[] = cached_clusterprims[itoa(nbor_cluster)];
int newclusterprims[];
append(newclusterprims, clusterprims);
append(newclusterprims, tmp);
int newcluster = nbor_cluster;
//printf("--- %d\n--- %d\n--- %d\n", clusterprims, tmp, newclusterprims);
//if(DEBUG==1) printf("\t\tnew clusterprims: %d\n",newclusterprims);
// update this cluster's prim data
foreach(int ncp; clusterprims)
{
cached_cluster[ncp] = nbor_cluster;
cached_area[ncp] = newarea;
}
// update dictionaries/etc
cached_clusterprims[itoa(newcluster)] = newclusterprims;
if(DEBUG==1) printf("\t-----------------------------\n\n");
}
}
//output data
for(int i=0; i<nprimitives(0); i++)
{
setprimattrib(0, "cluster", i, cached_cluster[i], "set");
setprimattrib(0, "area", i, cached_area[i], "set");
}
There’s a lot of debug text in there from my iterating, but it is relatively simpler than before, which is a good sign. Basically, get the cached data, then iterate clusters, take the precalculated neighbour data, and based on the pair, setup new data. There’s a small issue where I think a cluster may get left below the threshold, which I will tackle next, but the main win in rearranging this algorithm is that now the large test data runs in 0.5 seconds. That’s 120x speed boost. 🙂 The large map is around 4000 clusters so this improvements is very welcomed.
I will post another update when I have fixed the last edge cases and bugs, but for now this is working nicely and I plan to develop an .hda to genericise the functionality as it may be useful in different contexts.